From Prototype to Production
The Zero-Trust Path for Agentic AI
Heath Emerson, MBA — Founder & CEO
February 2026 | apotheon.ai
Download Full PDF
Get the complete whitepaper with references and citations
Executive Summary
The agentic AI market has entered a critical inflection point. Global spending on AI systems is projected to reach $300 billion by 2026. Four out of five enterprises are adopting AI agents, and 90% plan budget increases. Yet the data tells a contradictory story: 95% of generative AI pilots fail to deliver measurable ROI, Gartner predicts over 40% of agentic AI projects will be canceled by 2027, and the S&P Global abandonment rate has surged from 17% to 42% in a single year.
The root cause is consistent: organizations build with frameworks optimized for developer velocity—LangGraph, CrewAI, OpenClaw—and discover too late that orchestration without governance is a prototype, not a product. The gap between working demo and regulated production spans identity management, policy enforcement, evidence chains, continuous testing, and observability—capabilities that no single agent framework provides natively.
This paper examines the production gap from three perspectives. First, it analyzes what open-source frameworks provide and where their design responsibilities end. Second, it maps the competitive landscape of governance solutions—runtime guardrails (Lakera, Prompt Security), AI governance platforms (Dataiku Govern, Credo AI), security testing (CalypsoAI, Protect AI), and observability (Arthur AI, Galileo)—assessing what each covers and what falls between the seams when enterprises assemble multi-vendor stacks. Third, it introduces Apotheon’s AIOS architecture as a unified alternative and evaluates its positioning against both individual competitors and multi-vendor combinations.
The analysis is intended to be useful regardless of which governance path an organization ultimately selects. The production gap is real, the regulatory deadlines are immovable, and the market needs honest assessment of available solutions.
The Production Gap: Why 95% of AI Pilots Fail
The data is stark and consistent across sources. A 2025 MIT study analyzing over 300 enterprise initiatives found that 95% of generative AI pilots fail to deliver measurable return on investment. The problem is not technical capability—the models work. RAND Corporation research confirms that AI projects fail at twice the rate of traditional IT projects, with the primary failure mode being organizational rather than algorithmic: insufficient governance, unclear accountability, and fragmented integration.
McKinsey’s 2025 AI maturity report found that 88% of organizations use AI, but only 6% qualify as high performers. The gap between usage and performance is governance infrastructure. Precisely and Drexel University found that only 12% of organizations report AI-ready data quality, and 70% cite governance as their top blocker. These are not technology problems—they are architecture problems.
The Five Production Blockers
Across conversations with CIOs, CTOs, and enterprise architects, five recurring blockers explain why pilots stall:
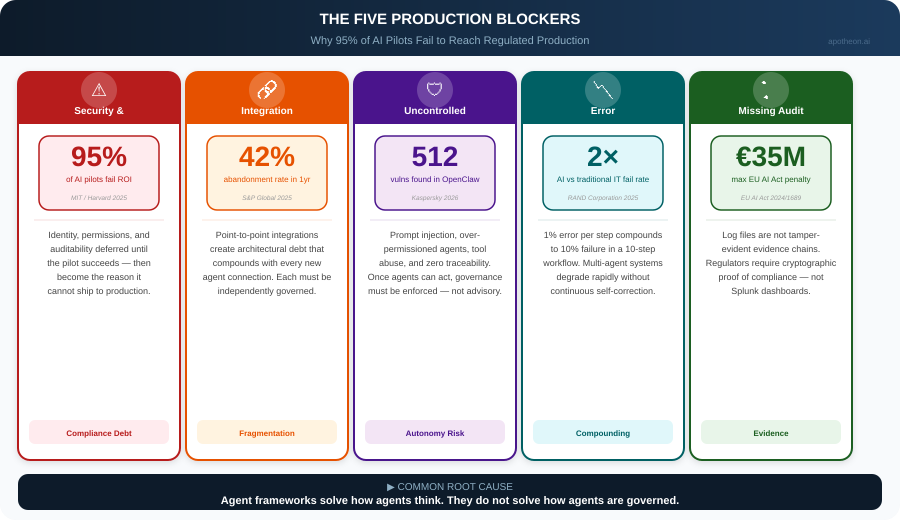
1. Security and compliance debt. It is easy to build a demo. It is hard to build something that can safely run in production. Identity, permissions, auditability, and governance get deferred until the pilot succeeds—then become the reason it cannot ship. The Gravitee State of AI Agent Security 2026 report, surveying over 900 executives, found that identity governance for non-human identities was the most underaddressed risk across enterprise AI deployments.
2. Integration fragmentation. Most enterprises operate across ERP, CRM, ITSM, data platforms, and custom systems. Agents built on open-source frameworks with point-to-point integrations create architectural debt that compounds with every new connection. Each integration must be independently governed, monitored, and secured.
3. Uncontrolled autonomy risk. CIOs and CISOs worry about prompt injection, over-permissioned agents, unintended actions, and lack of traceability. Once agents can act through APIs and tools, governance cannot be advisory—it must be enforced in the execution path.
4. Error compounding. Even small error rates compound across multi-step agentic processes. A 1% error rate per step becomes a 10% failure rate in a ten-step workflow. Without continuous monitoring and self-correction, multi-agent systems degrade rapidly. METR research shows AI task duration is doubling every seven months—making compound error an accelerating risk.
5. Missing audit evidence. Regulated industries require tamper-evident evidence chains, not log files. When a regulator asks for proof that an AI agent complied with HIPAA across 10 million patient interactions, a Splunk dashboard is not sufficient. The EU AI Act, with full high-risk compliance required by August 2, 2026, mandates documented adversarial testing and continuous risk assessment with penalties reaching €35 million or 7% of global annual revenue.
What Open-Source Frameworks Actually Provide
To understand the production gap concretely, it is necessary to examine what today’s leading agent frameworks offer—and where their responsibilities end. This is not a criticism of these frameworks. They are excellent at what they were designed to do. The issue is that what they were designed to do is not sufficient for regulated production.
LangGraph / LangChain
LangGraph provides graph-based orchestration where agent workflows are defined as stateful directed graphs. Nodes represent computation steps, edges represent transitions, and state is managed across invocations. LangSmith adds observability and tracing. The framework excels at developer experience—it is well-documented, widely adopted, and integrates with every major LLM provider. Where LangGraph ends: identity management is delegated to the deploying organization; policy enforcement exists only through custom callback implementations; audit trails are application logs, not cryptographic evidence; there is no native governance layer for regulated compliance.
CrewAI
CrewAI’s role-based multi-agent model assigns specialized roles to agents that collaborate in crews. With over 44,000 GitHub stars and claimed adoption by 60% of Fortune 500 companies, it has achieved significant market penetration. CrewAI’s strength is rapid multi-agent prototyping—standing up a research-writer-editor pipeline takes minutes. Where CrewAI ends: agent autonomy is constrained only by prompt design, not infrastructure controls; inter-agent communication is unmonitored by default; there is no tenant isolation, identity verification, or compliance evidence generation.
OpenClaw and the Open-Source Frontier
OpenClaw, the open-source autonomous agent that accumulated over 200,000 GitHub stars by early 2026, demonstrated both the potential and the peril of ungoverned agents. Users reported agents clearing disks, rewriting configurations, and executing unintended actions. A Kaspersky security audit identified 512 vulnerabilities. OpenClaw’s speed of adoption proved market demand for autonomous AI; its security profile proved that demand without governance creates risk. As Institutional Investor warned, OpenClaw may be the AI agent institutional investors need to understand—but should not touch.
The Common Pattern
Every major open-source framework follows the same design philosophy: maximize developer velocity for orchestration while delegating governance to the deploying organization. This is a rational design choice for open-source projects—governance requirements vary enormously across industries and jurisdictions. But it means that every enterprise deploying these frameworks must build or buy the governance layer separately. The question is whether to build it from scratch, assemble it from multiple specialized vendors, or adopt a unified platform.

The AI Governance Competitive Landscape
The market for AI governance and security has expanded rapidly, fragmenting into specialized categories. Understanding what each category covers—and what falls between the seams—is essential for organizations evaluating their options. This analysis examines the major categories and leading vendors with an emphasis on honest capability assessment.
Runtime Guardrails: Lakera Guard, Prompt Security, Akamai Firewall for AI
Runtime guardrail platforms intercept prompts and model outputs at inference time, applying real-time threat detection to block prompt injection, data leakage, and harmful content. Lakera Guard is the category leader, offering model-agnostic, low-latency protection with both SaaS and self-hosted deployment. Prompt Security provides a GenAI-first platform with browser integrations and MCP-aware agent protection. Akamai’s offering leverages its CDN infrastructure for edge-deployed AI firewalling.
What these platforms do well: Input/output filtering at inference time with sub-second latency. PII detection and redaction. Known prompt injection pattern detection. Jailbreak prevention. Content policy enforcement. These are mature, well-tested capabilities that solve real problems.
What falls outside their scope: Runtime guardrails operate at the request/response boundary. They do not provide agent identity management, workflow orchestration, memory governance, multi-step evidence chains, adversarial red-teaming, or compliance documentation generation. An organization using Lakera Guard has excellent prompt-level protection but no answer for the EU AI Act’s requirement for documented adversarial testing or tamper-evident audit trails.
AI Governance Platforms: Dataiku Govern, Credo AI, IBM watsonx.governance
Governance platforms provide policy management, risk cataloging, compliance documentation, and lifecycle oversight for AI systems. Dataiku was named a Leader in the IDC MarketScape for Worldwide Unified AI Governance Platforms 2025–2026, offering embedded governance controls throughout the AI lifecycle. Credo AI focuses on policy-to-control mapping and auditable evidence. IBM watsonx.governance provides enterprise-grade model monitoring and bias detection.
What these platforms do well: Policy authoring and management. Risk assessment workflows. Compliance mapping to EU AI Act, NIST AI RMF, and ISO 42001. Model monitoring for drift and bias. Audit trail generation. These platforms excel at the organizational governance layer—the policies, processes, and documentation that regulated industries need.
What falls outside their scope: Governance platforms typically operate above the runtime layer. They define what should happen but do not enforce it in the execution path of an AI agent. They do not provide cryptographic evidence chains, real-time policy enforcement at the agent action level, adversarial red-teaming, or runtime guardrails. An organization using Dataiku Govern has excellent governance documentation but needs additional tooling to enforce those policies in the hot path of agent execution.
AI Security Testing: CalypsoAI, Protect AI, HiddenLayer
Security testing platforms provide automated red-teaming, vulnerability scanning, and adversarial testing for AI systems. CalypsoAI focuses on securing agentic systems at the cognitive layer, analyzing agent reasoning before execution. Protect AI (now part of Cisco’s portfolio following the Robust Intelligence acquisition) provides model scanning, supply chain security with AI Bill of Materials, and runtime protection via Guardian. HiddenLayer monitors agent workflows and chained tool invocations to detect multi-step exploitation.
What these platforms do well: Automated adversarial testing against prompt injection, jailbreaks, and data leakage. Model vulnerability scanning. Supply chain security assessment. Agent-specific risk testing including tool abuse and privilege escalation. These capabilities directly address the EU AI Act’s requirement for documented adversarial testing.
What falls outside their scope: Security testing platforms identify vulnerabilities but do not provide the governance runtime that prevents exploitation in production. They do not offer agent orchestration, memory management, identity verification, or compliance evidence chains. An organization using CalypsoAI has excellent pre-deployment testing but needs separate tooling for runtime enforcement, governance documentation, and audit trail generation.
AI Observability: Arthur AI, Galileo, Langfuse
Observability platforms monitor AI systems in production, detecting hallucinations, drift, policy violations, and performance degradation. Arthur AI provides enterprise-grade monitoring with bias and fairness detection. Galileo focuses on hallucination detection and RAG evaluation. Langfuse offers open-source LLM observability with tracing and evaluation capabilities.
What these platforms do well: Real-time monitoring of model outputs. Hallucination detection. Performance tracking and alerting. Cost monitoring. Trace analysis across multi-step agent workflows. These are essential operational capabilities for any production AI system.
What falls outside their scope: Observability platforms detect problems but do not prevent them. They do not enforce policies in the execution path, provide cryptographic audit trails, manage agent identity, or generate compliance documentation. An organization using Galileo knows when something goes wrong but depends on other tooling to ensure it does not happen in the first place.
The Multi-Vendor Stack Problem
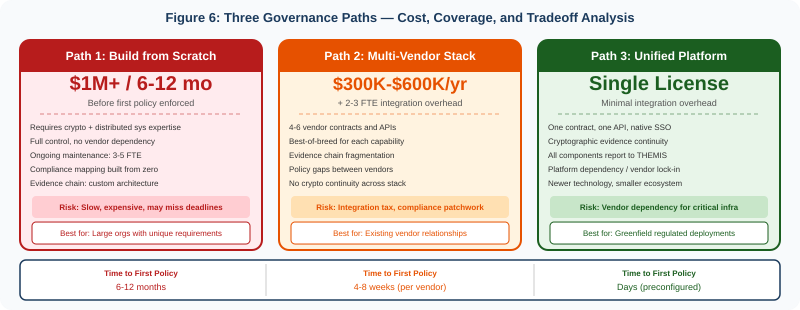
For enterprises in regulated industries, no single specialized vendor covers the full governance requirement. This forces organizations into one of three paths: build governance infrastructure from scratch (requiring cryptography, distributed systems, and compliance engineering expertise), assemble a multi-vendor stack from specialized solutions, or adopt a unified platform.
The multi-vendor approach is the most common and the most problematic. A typical enterprise attempting to achieve comprehensive AI governance might combine Lakera Guard for runtime guardrails, CalypsoAI or Protect AI for adversarial testing, Dataiku Govern or Credo AI for governance documentation, Arthur AI or Galileo for observability, and a custom identity layer or SGNL for NHI management—plus the agent framework itself. This creates five to six vendor relationships, five to six integration surfaces, five to six authentication schemes, and five to six sources of truth for compliance evidence.

Where Multi-Vendor Stacks Break Down
Evidence chain fragmentation: Each vendor generates its own logs and audit records in its own format. When a regulator asks for the complete evidence chain—from agent identity verification through policy evaluation to action execution to outcome recording—the organization must stitch together records from multiple systems, each with different schemas, timestamps, and integrity guarantees. There is no cryptographic continuity across the stack.
Policy enforcement gaps: Governance platforms define policies. Runtime guardrails enforce prompt-level controls. But the gap between policy definition and runtime enforcement—the translation of organizational policy into per-action enforcement—falls between vendors. Who ensures that the PII redaction policy defined in Credo AI is actually enforced at the Lakera Guard level? Who verifies that the adversarial weaknesses CalypsoAI discovered have been patched in the runtime guardrails?
Identity inconsistency: Agent identity is typically managed at the framework level (API keys, service accounts) rather than the governance level. When a multi-step agent workflow crosses from LangGraph orchestration through Lakera guardrails to Galileo monitoring, each system may have a different understanding of who the agent is, what permissions it holds, and what tenant context applies.
Integration tax: Every vendor relationship carries operational cost—contract management, SSO integration, API versioning, incident response coordination, upgrade testing, and procurement cycles. For a six-vendor governance stack, this overhead is substantial and ongoing. Forrester estimates that integration overhead adds 30-40% to the total cost of multi-vendor security architectures.
The AI security market is fragmenting into specialized layers: guardrails, governance, testing, observability, and identity. Each layer is necessary. The question is whether assembling them from separate vendors produces a coherent governance architecture—or a compliance patchwork with gaps between every seam.
Zero Trust for AI Agents: The Architectural Requirement
Zero Trust Architecture, codified in NIST SP 800-207 and now mandated across federal agencies through the NSA’s Zero Trust Implementation Guidelines (January 2026), operates on a foundational principle: never trust, always verify. The Cloud Security Alliance’s Agentic Trust Framework (ATF), published in February 2026, extends Zero Trust principles specifically to AI agents, introducing a maturity model where agents earn trust through continuous verification rather than inheriting it from network position.
For agentic AI, Zero Trust means that every action—whether a prompt, API call, tool invocation, or data retrieval—must be authenticated, authorized, and recorded. Access is dynamically assigned using just-in-time permissions based on context, behavior, and risk posture. No agent is trusted by default, regardless of where it runs or who deployed it.
This requirement cuts across every governance category: identity management (who is this agent?), policy enforcement (is this action authorized?), evidence recording (can we prove what happened?), and continuous verification (has the agent’s behavior changed?). No specialized vendor covers all four. A unified platform must.
AIOS Architecture: A Unified Approach
Apotheon’s AIOS platform was designed to address the multi-vendor stack problem by providing governance, orchestration, security testing, memory management, and observability as an integrated architecture rather than a collection of point solutions. This section describes the architecture objectively, acknowledging where it excels and where it carries the inherent tradeoffs of a unified platform approach.
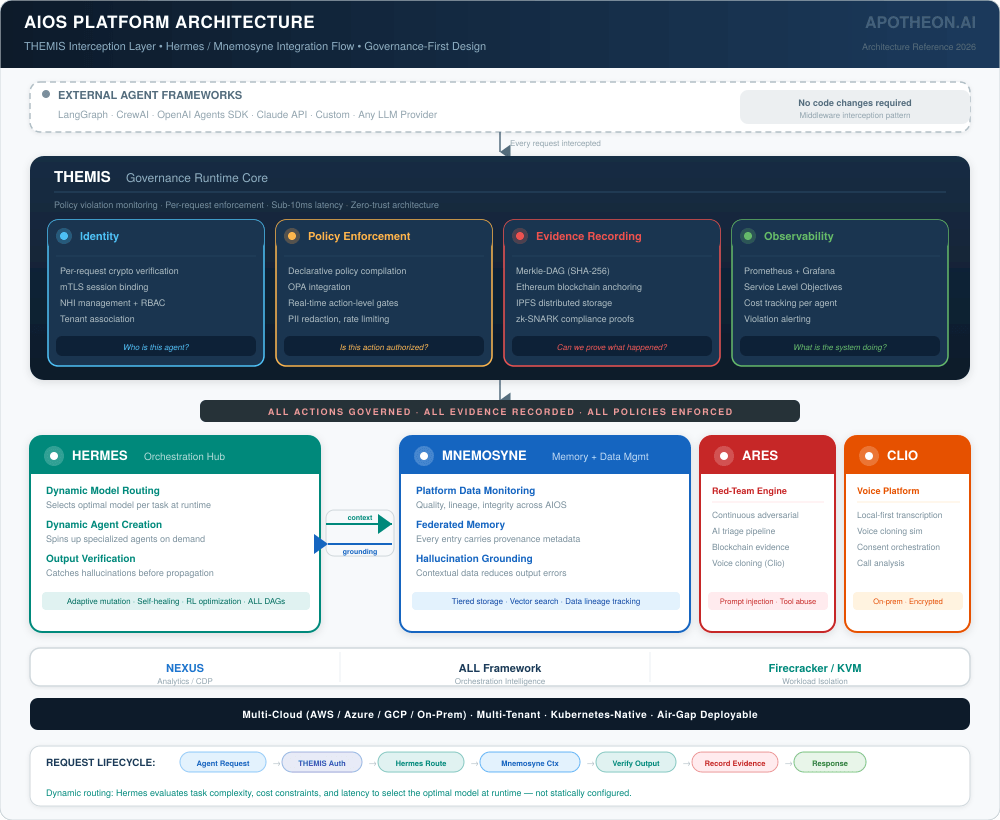
THEMIS: Governance Runtime
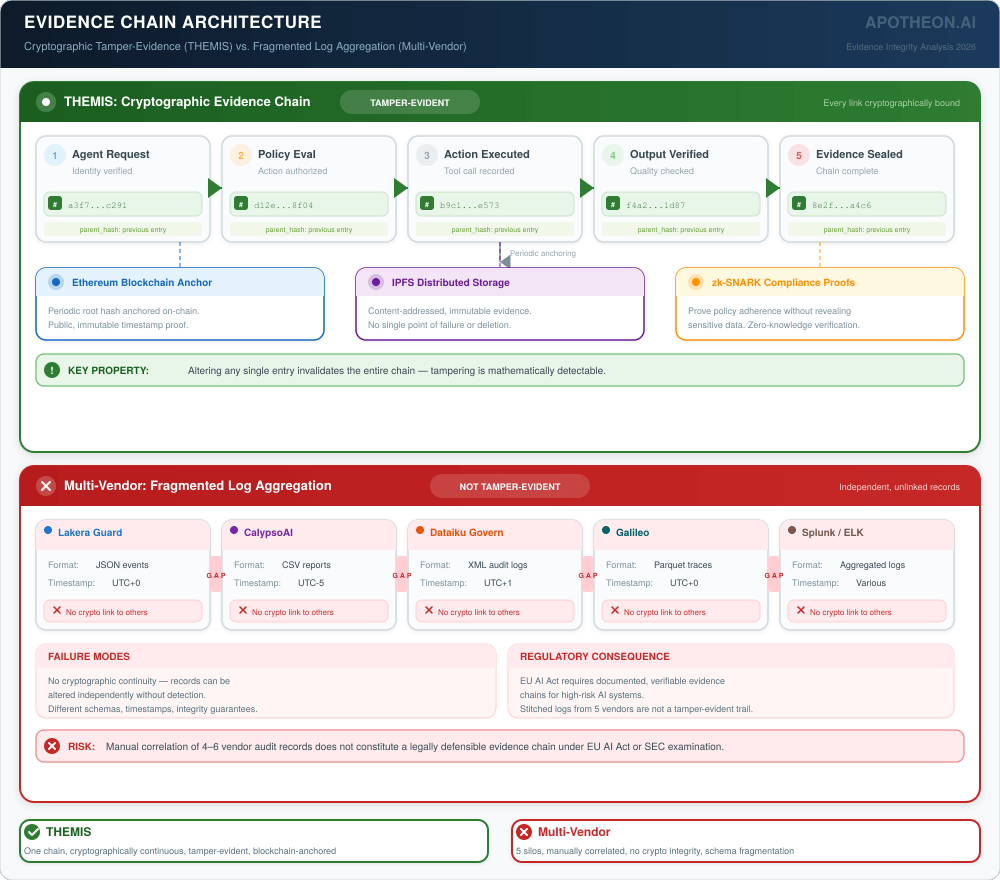
THEMIS operates as middleware that intercepts agent actions at the execution boundary—wrapping any agent framework (LangGraph, CrewAI, custom) without requiring framework code changes. It provides four layers: cryptographic identity verification per request (not API-key authentication but per-request identity validation with session binding and mTLS), declarative policy enforcement evaluated at action time (not post-hoc), Merkle-DAG evidence recording with external blockchain anchoring, and real-time observability through Prometheus and Grafana integration.
Honest assessment: THEMIS’s strength is the integration of identity, policy, evidence, and observability in a single runtime. Its cryptographic evidence chain—Merkle-DAG entries with SHA-256 hashing, Ethereum anchoring, and IPFS storage—provides stronger tamper-evidence than any log-based approach. The tradeoff is architectural coupling: organizations adopt THEMIS as their governance layer, which creates dependency on a single vendor for a critical infrastructure component. This is the same tradeoff enterprises make with any infrastructure platform (AWS, Azure, Snowflake)—but it is a tradeoff that should be acknowledged.
Supporting Components
Hermes (Orchestration): Executes ALL Framework DAGs with adaptive mutation, self-healing, and RL-driven optimization. Hermes supports dynamic model usage—selecting and routing to optimal models per task at runtime—and dynamic agent creation, spinning up specialized agents on demand based on workflow requirements. Working with Mnemosyne, Hermes handles hallucination detection and output verification as part of the orchestration pipeline itself, catching errors before they propagate downstream. The tradeoff: organizations using AIOS orchestration cannot simultaneously use their existing framework’s orchestration—though THEMIS can wrap external frameworks without requiring Hermes adoption.
Mnemosyne (Memory and Data Management): Federated AI memory with data lineage tracking across tiered storage. Every memory entry carries provenance metadata. Beyond memory governance, Mnemosyne monitors and manages all platform data—tracking data quality, lineage, and integrity across the AIOS ecosystem. Paired with Hermes, Mnemosyne provides the contextual grounding that enables output verification and hallucination reduction at the orchestration layer. No commercial competitor offers purpose-built AI memory and data management governance—most organizations build custom solutions or rely on vector databases without lineage tracking.
Ares (Security Testing): Continuous red-teaming with AI triage, covering prompt injection, tool abuse, memory poisoning, RAG corruption, and voice cloning via Clio integration. Competes with CalypsoAI and Protect AI on adversarial testing but adds blockchain-notarized evidence and voice cloning capabilities that neither competitor offers.
Competitive Comparison: Individual Vendors
The following comparisons assess specific capability overlaps between AIOS components and leading competitors. The goal is honest positioning—acknowledging where competitors lead and where AIOS differentiates.
| Capability | Lakera Guard | CalypsoAI | Dataiku Govern | AIOS (Apotheon) |
|---|---|---|---|---|
| Runtime guardrails | Leader: sub-ms latency, model-agnostic, mature | Strong: cognitive-layer interception | Limited: governance layer, not runtime | THEMIS: policy gates in execution path |
| Adversarial testing | Not core: basic injection detection | Strong: agentic red-teaming, MCP audit | Not core: compliance-focused | Ares: continuous + voice cloning + blockchain evidence |
| Governance / policy | Limited: content policies only | Moderate: execution safeguards | Leader: IDC MarketScape leader, full lifecycle | THEMIS: declarative policies, compiled to enforcement |
| Agent identity | Not provided | Limited: framework-level | User/role-level only | THEMIS: per-request crypto identity, NHI management |
| Evidence chain | Application logs | Audit reports | Compliance documentation | Merkle-DAG + Ethereum + IPFS + zk-SNARKs |
| Observability | Basic metrics | Post-execution analytics | Model monitoring, drift | THEMIS + Prometheus/Grafana, native SLOs |
| Orchestration | Not provided | Not provided | Not provided (wraps MLOps) | Hermes: dynamic agents, dynamic models, ALL DAGs |
| Memory / data mgmt | Not provided | Not provided | Not provided | Mnemosyne: federated memory, data governance |
| Hallucination / output | Not provided | Not provided | Not core | Hermes + Mnemosyne: orchestration-layer verification |
| Voice / social eng. | Not provided | Not provided | Not provided | Ares + Clio: AI voice cloning simulation |
Where Competitors Lead
Honest assessment requires acknowledging competitive strengths. Lakera Guard has deeper prompt injection detection than THEMIS’s policy gates—they have invested heavily in adversarial ML research specifically for input sanitization. Dataiku Govern has broader enterprise adoption and a more mature governance UI for non-technical compliance teams—IDC’s Leader designation reflects real capability. CalypsoAI’s cognitive-layer interception is architecturally innovative for agent-specific security. Protect AI’s supply chain security (AI Bill of Materials) addresses a risk category that AIOS does not currently cover. These are real strengths that organizations should evaluate.
Where AIOS Differentiates
AIOS’s differentiation is architectural rather than feature-level. No competitor offers cryptographic evidence chains with blockchain anchoring as a native capability—this is the strongest evidence integrity available for regulatory compliance. No competitor integrates runtime guardrails, adversarial testing, governance policy enforcement, agent identity management, memory and data governance, and orchestration in a single platform—eliminating the multi-vendor integration tax. No competitor offers AI voice cloning simulation for social engineering resilience testing. No competitor embeds hallucination detection and output verification into the orchestration layer itself—Hermes and Mnemosyne treat output quality as an orchestration concern, not a separate monitoring afterthought. And Hermes’s dynamic model usage and dynamic agent creation enable workflows that adapt their own composition at runtime—a capability that static orchestration frameworks cannot match.
Competitive Comparison: Multi-Vendor Stacks
The more relevant comparison for enterprise buyers is not AIOS versus any single competitor, but AIOS versus the multi-vendor stack required to achieve equivalent coverage.
Stack A: Lakera + CalypsoAI + Dataiku Govern + Arthur AI
Coverage: Runtime guardrails (Lakera) + adversarial testing (CalypsoAI) + governance documentation (Dataiku) + observability (Arthur). This covers four of the five governance layers well.
Gaps: No cryptographic evidence chain connecting the four systems. No agent identity management below API keys. No memory governance. No orchestration integration. No voice cloning simulation. Four vendor contracts, four integration surfaces, four sources of audit evidence that must be manually correlated.
Estimated cost: Four enterprise licenses plus integration engineering. Likely $300K–$600K annually plus 2–3 FTE for integration maintenance.
Stack B: Protect AI + Credo AI + Galileo + SGNL
Coverage: Security testing and supply chain (Protect AI) + policy-to-control governance (Credo AI) + hallucination monitoring (Galileo) + NHI identity management (SGNL/CrowdStrike). Broader identity coverage than Stack A.
Gaps: No runtime guardrails at inference time. No agent orchestration. No memory governance. No social engineering simulation. Same evidence chain fragmentation. Five vendor contracts.
Estimated cost: Similar range with SGNL adding significant licensing cost following CrowdStrike’s $740M acquisition.
AIOS: Unified Platform
Coverage: THEMIS (identity + policy + evidence + observability) + Ares (adversarial testing + voice cloning) + Hermes (orchestration + dynamic agents/models + output verification) + Mnemosyne (memory + data governance + hallucination grounding) + Clio (voice). Full governance stack with cryptographic continuity.
Gaps: Narrower prompt injection ML research than Lakera’s specialized focus. Less mature governance UI than Dataiku’s established platform. No AI Bill of Materials capability (Protect AI’s strength). Vendor lock-in risk inherent in unified platforms.
Estimated cost: Single platform license. Significantly lower integration overhead. Platform dependency tradeoff.
The choice between multi-vendor stacks and unified platforms is not primarily a feature comparison—it is an architectural decision about whether governance evidence should be cryptographically continuous across the entire agent lifecycle or stitched together from independent systems after the fact.
The Zero-Trust Maturity Path
Regardless of which governance approach an organization selects, the Cloud Security Alliance’s Agentic Trust Framework defines a progressive maturity model that provides useful staging for adoption.
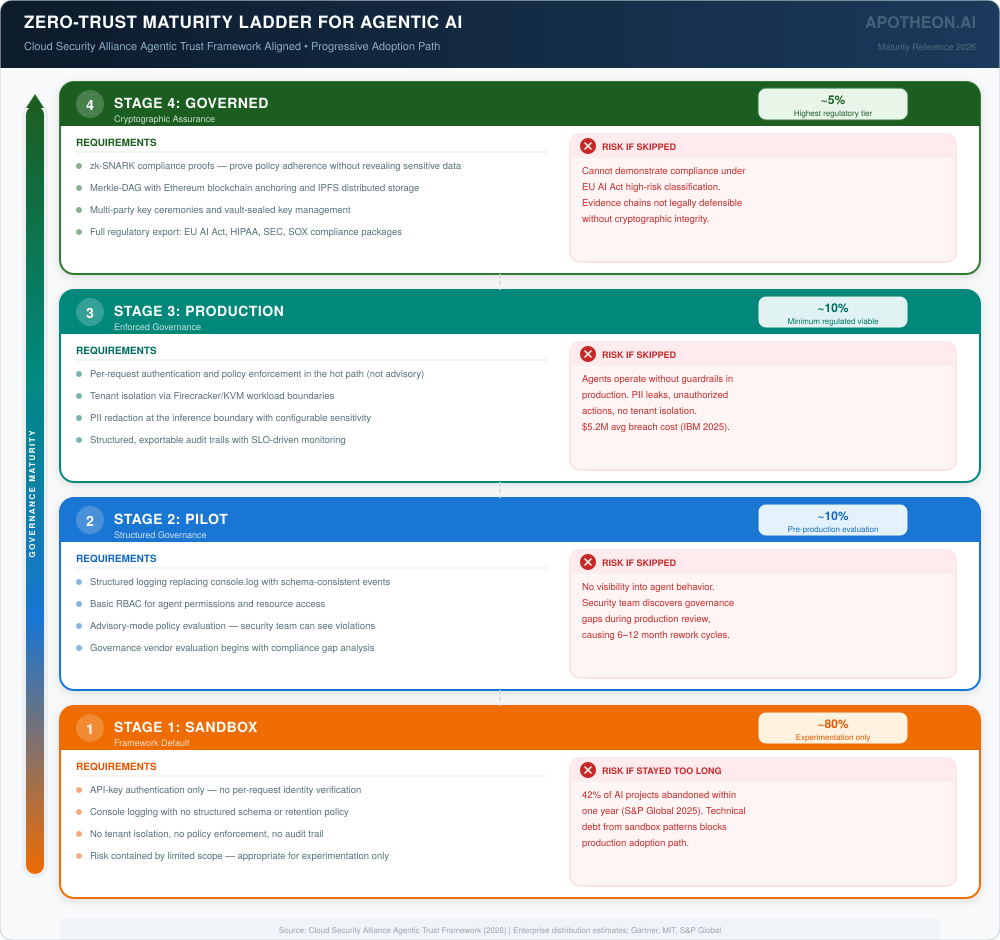
Stage 1: Sandbox (Framework Default)
This is where most organizations begin and where approximately 80% remain. The agent runs locally or in a development environment with API-key authentication, console logging, and no tenant isolation. Risk is contained by limited deployment scope. This stage is appropriate for experimentation and proof-of-concept. Any governance investment at this stage is premature.
Stage 2: Pilot (Structured Governance)
Structured logging, basic RBAC, and policy evaluation in advisory mode (log violations without blocking). This gives security teams visibility into agent behavior without disrupting development velocity. At this stage, organizations should begin evaluating governance solutions—whether specialized vendors, multi-vendor stacks, or unified platforms—based on their regulatory requirements and integration constraints.
Stage 3: Production (Enforced Governance)
Per-request authentication, policy enforcement in the hot path, tenant isolation, PII redaction, and rate limiting become mandatory. Audit trails are structured and exportable. This is the minimum viable governance for regulated industries and the threshold where the multi-vendor integration tax becomes operationally significant. Organizations at this stage need runtime guardrails, policy enforcement, and evidence generation working together—the question is whether that integration comes from vendor assembly or platform architecture.
Stage 4: Governed (Cryptographic Assurance)
Full cryptographic governance: tamper-evident evidence chains with external anchoring, zero-knowledge compliance proofs, vault-sealed key management, continuous control monitoring, and multi-party key ceremonies. This is the standard required for healthcare AI with HIPAA obligations, financial services with SEC examination requirements, and any organization deploying high-risk AI systems under the EU AI Act. At this stage, the evidence chain integrity requirement effectively eliminates multi-vendor approaches that cannot provide cryptographic continuity—unless organizations are willing to build custom integration layers.
The Cost of Inaction vs. the Cost of Governance
The Cost of Inaction
The data quantifies what happens without governance. The average data breach costs $5.2 million, with costs 38% higher for organizations without zero-trust implementation. AI-powered attacks have increased 53% in 2025 alone. The World Economic Forum’s Global Cybersecurity Outlook 2026 reports that 73% of organizations were directly affected by cyber-enabled fraud. Gartner’s prediction that over 40% of agentic AI projects will be canceled by 2027 means that the cost of governance failure is not just security exposure—it is project death.
The Cost of Governance
Governance adds operational cost regardless of approach. Multi-vendor stacks carry licensing costs ($300K–$600K+ annually for enterprise coverage), integration engineering (2–3 FTE ongoing), and coordination overhead. Unified platforms carry licensing costs (typically lower per-capability) but vendor dependency. Building from scratch requires deep cryptography, distributed systems, and compliance engineering expertise—typically 6–12 months and $1M+ in engineering investment before the first policy is enforced.
The asymmetry is clear: the cost of governance is measured in licensing fees, integration overhead, and architectural decisions. The cost of its absence is measured in regulatory fines (€35M under EU AI Act), reputational damage, project cancellation, and the 40% failure rate that Gartner predicts for ungoverned agentic AI.
Conclusion: Governed Agents Are the Only Production Agents
The open-source agent framework ecosystem has achieved remarkable things. LangGraph, CrewAI, and their peers have made it possible for any developer to build multi-agent systems that would have been research projects five years ago. The governance vendor ecosystem has responded with increasingly capable specialized solutions—Lakera for runtime protection, Dataiku for lifecycle governance, CalypsoAI for adversarial testing, Arthur AI for observability.
But orchestration without governance is a prototype, not a product. And governance assembled from fragmented vendors is documentation, not assurance. The five blockers that kill agentic AI projects—security debt, integration fragmentation, uncontrolled autonomy, error compounding, and missing audit evidence—require architectural solutions, not product additions.
The market offers three paths: build from scratch (expensive, slow, high expertise required), assemble from specialized vendors (broader coverage, integration complexity, evidence fragmentation), or adopt a unified platform (architectural coherence, vendor dependency, newer technology). Each path has legitimate tradeoffs that depend on organizational constraints, regulatory requirements, and risk tolerance.
Apotheon’s AIOS platform represents one answer to the unified platform path—designed from its research foundations for cryptographic governance integrity across the full agent lifecycle. It is not the only answer. But the question itself—how to bridge the gap from prototype to governed production—is the question that will determine which agentic AI projects survive and which join the 40% that Gartner predicts will be canceled.
For the enterprises that get the governance architecture right, agentic AI will transform their operations. For those that do not, the prototypes will remain prototypes.
Learn more at apotheon.ai | Request a governance architecture assessment
References
[1] Gartner, Inc. (June 2025). “Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027.” Press Release.
[2] MIT Sloan / Harvard Business School (2025). “95% of Enterprise AI Pilots Fail to Deliver Expected Returns.” Study of 300+ enterprise initiatives.
[3] RAND Corporation (2025). “AI Projects Fail at Twice the Rate of Traditional IT Projects.” Research Report.
[4] S&P Global Market Intelligence (2025). AI Initiative Abandonment: 17% (2024) to 42% (2025). Market Survey.
[5] Precisely & Drexel University (2025). “Only 12% of Organizations Report AI-Ready Data Quality; 70% Cite Governance as Top Blocker.”
[6] PwC (2025). “4 Out of 5 Companies Adopting AI Agents; 90% Planning Budget Increases.” AI Enterprise Survey.
[7] McKinsey & Company (2025). “88% of Organizations Use AI, But Only 6% Are High Performers.” AI Maturity Report.
[8] METR (2025). “AI Task Duration Doubling Every Seven Months.” Autonomous Capabilities Research.
[9] Gravitee (February 2026). “State of AI Agent Security 2026 Report.” Survey of 900+ Executives and Practitioners.
[10] Cloud Security Alliance (February 2026). “The Agentic Trust Framework: Zero Trust Governance for AI Agents.” ATF v1.0.
[11] NIST SP 800-207. “Zero Trust Architecture.” National Institute of Standards and Technology.
[12] NSA (January 2026). Zero Trust Implementation Guidelines (ZIGs).
[13] IDC MarketScape (December 2025). “Worldwide Unified AI Governance Platforms 2025–2026 Vendor Assessment.” Dataiku named Leader.
[14] Gartner Peer Insights (2026). AI Governance Platforms market reviews.
[15] Reco.ai (December 2025). “Top AI Security Posture Management Platforms for 2026.” Multi-vendor analysis.
[16] AI Multiple Research (2026). “AI Agent Security: 7+ Tools to Reduce Risk in 2026.” Vendor comparison.
[17] Artificial Intelligence News (January 2026). “Top 10 AI Security Tools for Enterprises in 2026.”
[18] Guardion.ai (2026). “AI Security Alternatives and Competitors 2026.” Market taxonomy.
[19] Kaspersky (January 2026). Security Audit of OpenClaw: 512 Vulnerabilities Identified.
[20] Institutional Investor (February 2026). “OpenClaw: The AI Agent Institutional Investors Need to Understand.”
[21] Forrester Research (2025). AI governance software spend forecast: quadrupling to $15.8B by 2030 (7% of AI software spend).
[22] IBM (2025). Cost of a Data Breach Report. Average breach cost: $5.2M; 38% higher without zero trust.
[23] World Economic Forum (2025). Global Cybersecurity Outlook 2026. 73% of organizations affected by cyber-enabled fraud.
[24] CrowdStrike (2025). Acquisition of SGNL for $740M (AI identity authorization).
[25] EU AI Act (2024). Regulation (EU) 2024/1689. Full high-risk compliance August 2, 2026. Penalties: €35M or 7% global revenue.
[26] SEC (November 2025). 2026 Examination Priorities: AI Governance and Cybersecurity.
[27] Apotheon.ai (2026). AIOS Platform Technical Documentation: THEMIS, Hermes, Mnemosyne, Ares, Clio, NEXUS.
Download Complete Whitepaper PDF
Get the full technical analysis including architecture diagrams, competitive comparison table, complete references, and implementation guidelines.